SCRAPY支援不同選擇器來將網頁的資料分離。
選擇器分為兩種:
-CSS
-XPATH
>>> response.xpath('//span/text()').get()
'good'
>>> response.css('span::text').get()
'good'
你如何在網頁中知道你該如何取得XPATH?
01.透過瀏覽器CHROMA或是FIREFOX
02.按下F12
03.透過圖片所示導引點取想要擷取的資訊
04.瀏覽器會跳到程式碼,你在程式碼上即可進行複製(複製XPATH位置)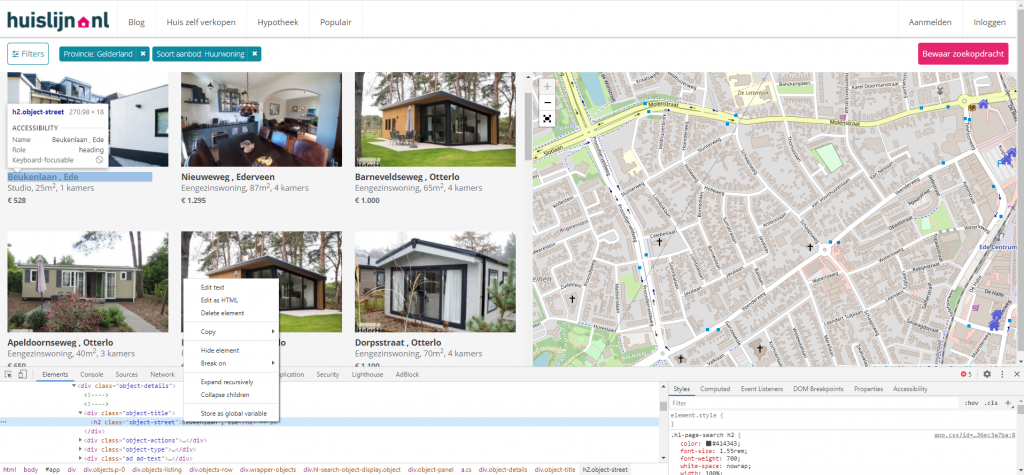
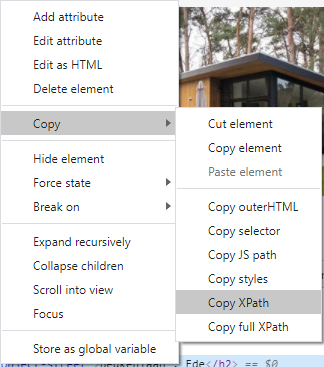
透過CHROMA複製(XPATH),此部分會先對應到ID部分
// *[ @ id = "app"] / div / div[2] / div[1] / div[2] / div[1] / div[1] / div / a / div[2] / div[1] / h2
透過CHROMA複製(完整XPATH)
/html/body/div[1]/div/div[2]/div[1]/div[2]/div[1]/div[1]/div/a/div[2]/div[1]/h2
透過FIREFOX
/html/body/div[2]/div/div[2]/div[1]/div[2]/div[1]/div[1]/div/a/div[2]/div[1]/h2
既然你已經知道了,你可以可以將此段加入程式碼中。
location1 = response.xpath('/html/body/div[2]/div/div[2]/div[1]/div[2]/div[1]/div[1]/div/a/div[2]/div[1]/h2/text()').extract()[0]
這樣即可以取到你想到的數值


 iThome鐵人賽
iThome鐵人賽